Website-Erstellung mit Ibexa: Query Field Type


Websites und Anwendungen enthalten eine Vielzahl von Listen unterschiedlicher Art. Das DXP-Speichermodul von Ibexa ermöglicht die Abfrage benutzerdefinierter Datenmodelle über die Such-API. Bisher wurden die Abfragen im Backend-Code durchgeführt, wodurch die Listen vom Rest des Content-Modells entkoppelt wurden. Mit Version 3.0 steht eine alternative Methode zur Verfügung: Query Field Type.
Bei dem Query Field Type handelt es sich um einen neuen Field Type für die Ibexa Content Engine. Er ermöglicht die Definition von Inhalten aus der Datenbank statt aus dem Code. Somit wird das Content-Modell enger mit den Content-Listings verknüpft. Für Administratoren entspricht die Arbeit mit dem Query Field Type jedem anderen Field Type wie Bild- oder Rich-Text.
Als praktisches Beispiel betrachten wir diesen vorliegen Blogpost. Blogs werden mit zwei Inhaltstypen erstellt: Blog und Blogpost. Das übergeordnete Blog ist ein Container für untergeordnete Elemente (wie diesen Beitrag, den Sie gerade lesen). Die Definition des Inhaltstyps "Post" nimmt den größten Teil der Zeit in Anspruch, die für die Definition und Erstellung benötigt wird: Er muss über die erforderlichen Felder wie Überschriften, Einleitung und Bilder sowie über Metadaten wie Tags und Autoren verfügen:
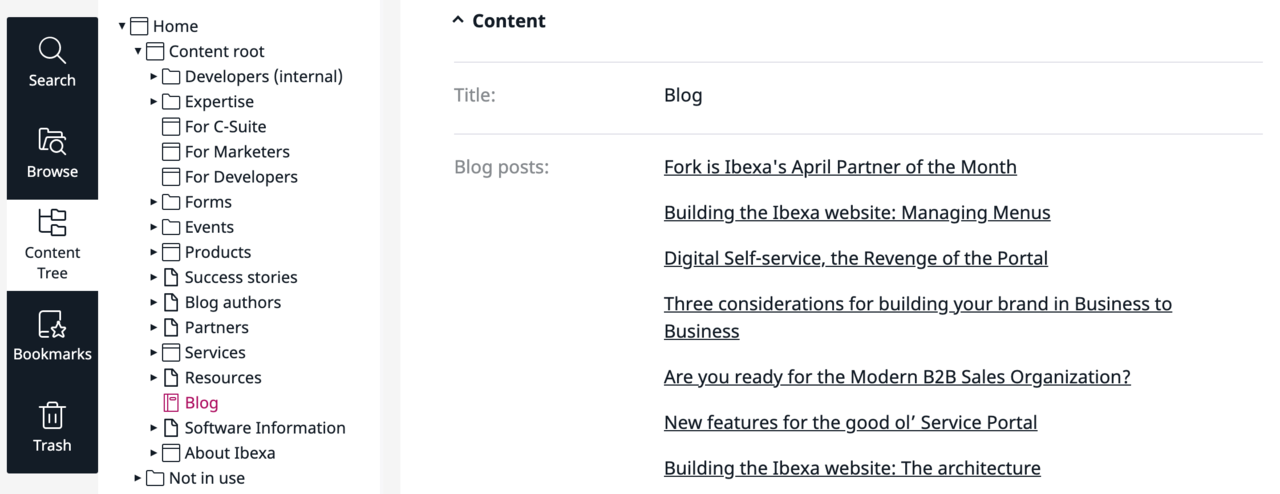
Der Container ist im Grunde nur eine äußere Struktur für alle Beiträge und umfasst nur sehr wenig Inhalt. Dies spiegelt sich in der Inhaltsstruktur wider, die im Wesentlichen nur aus Metadaten besteht:
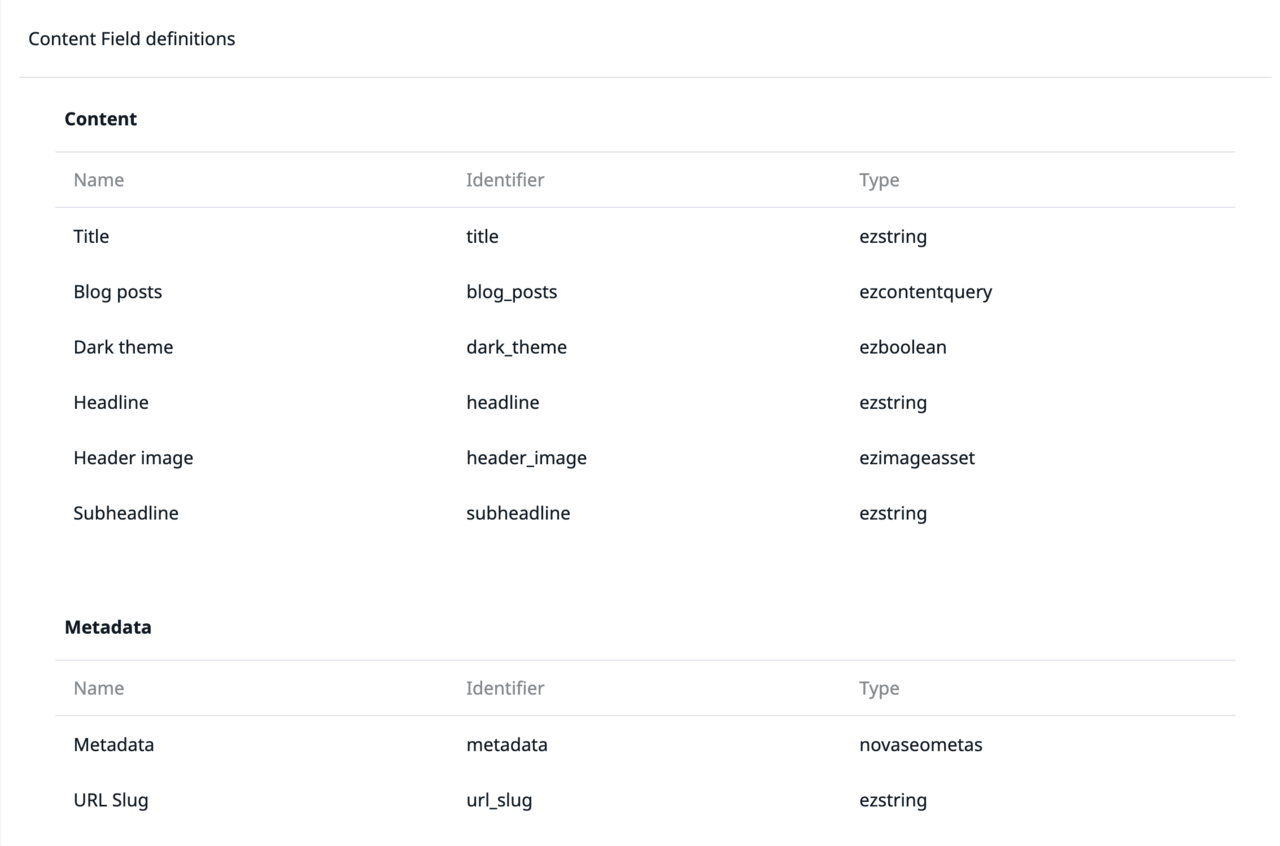
Der interessante Teil hier ist "Blog posts". Dies ist ein Query Field Type, der eine Auflistung anhand von Parametern durchführt. Er ermöglicht die Definition von Beziehungen, die über die standardmäßige hinausgehen, welche wir als Zusatzprodukt innerhalb des Content Trees erhalten. Im Backend enthält der Field Type einige Konfigurationsoptionen, die nur für diesen gelten:
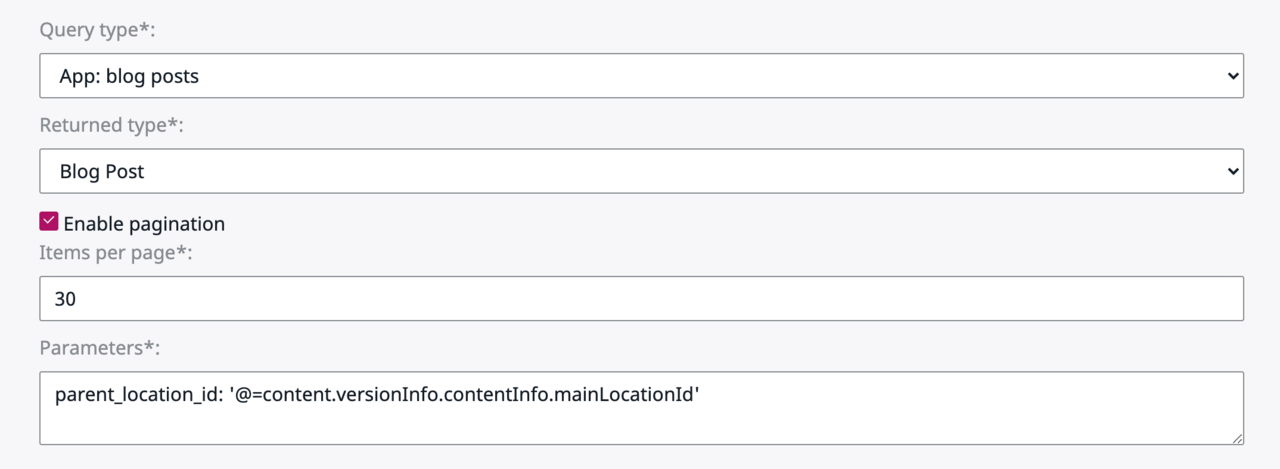
Der Query Type erlaubt die Abfrage entweder aus den eingebauten Query Types oder alternativ aus den von Ihnen erstellten. Hier verwenden wir unseren eigenen Abfragetyp, um eine benutzerdefinierte Sortierung zu ermöglichen (mehr dazu später). Der Rückgabewert legt fest, welche Daten zurückgegeben werden. Diese Informationen werden verwendet, um automatisch GraphQL-API-Schemata zu generieren, damit der Query-Typ für Headless Use Cases verwendet werden kann.
Paginierung aktivieren und Elemente pro Seite werden verwendet, um automatisch eine Seitennummerierung bereitzustellen, wenn die Ansicht auf der Serverseite gerendert wird. Das Feld Parameters gestattet die Übergabe von Parametern an den Query Type. Diese können sowohl statisch pro Seite als auch dynamisch sein, basierend auf dem angezeigten Ort und dem Content-Objekt. In unserem Fall verwenden wir den aktuellen Standort, um mehrere Blogs zu aktivieren, d. h. unseren Hauptblog und den Tech-Blog.
Auf der Serverseite verwenden wir einen einzigen gemeinsamen Abfragetyp für verschiedene Anwendungsfälle, z. B. für die Auflistung der Blogposts und die neuesten Blogposts am Ende der Seite. Falls es Sie interessiert, die Hauptmethode unseres BlogPostsQueryType lautet wie folgt:
public function getQuery(array $parameters = []): LocationQuery
{
$criteria = [
new Query\Criterion\Visibility(Query\Criterion\Visibility::VISIBLE),
new Query\Criterion\ContentTypeIdentifier('blog_post'),
];
if (!empty($parameters['path_string'])) {
$criteria[] = new Query\Criterion\Subtree($parameters['path_string']);
}
if (!empty($parameters['parent_location_id'])) {
$criteria[] = new Query\Criterion\ParentLocationId($parameters['parent_location_id']);
}
if (!empty($parameters['excluded_post_ids'])) {
$criteria[] = new Query\Criterion\LogicalNot(
new Query\Criterion\ContentId($parameters['excluded_post_ids'])
);
}
$options = [
'filter' => new Query\Criterion\LogicalAnd($criteria),
'sortClauses' => [
new SortClause\Field('blog_post', 'publish_date',Query::SORT_DESC)
]
];
return new LocationQuery($options);
}Neben der Vereinfachung unserer Codebasis und der Möglichkeit, die Auflistungsdefinition an unsere Content-Engine zu binden, ermöglicht die Verwendung des Query Types auch eine bessere Bedienung im Backend. Ihre Abfragetypen haben möglicherweise eine andere Sortierung als die des standardmäßigen Content Trees. Dies kann zu Irritationen bei der Verarbeitung der Daten führen.
In unserem Fall haben wir alle Blogeinträge aus der Baumstruktur ausgeblendet und die Benutzer verwenden stattdessen die Listenansicht des Abfragetyps. Dadurch wird sichergestellt, dass die Sortierschnittstelle der Verwaltung immer die öffentliche Ansicht widerspiegelt. Denn die Sortierlogik wird von beiden gemeinsam genutzt.
Der Field Type Content Query ist ein neuer Ansatz für die Implementierung von Inhalts- und Datenlisten in Ibexa DXP. Diese Methode verwenden wir überall dort, wo wir Inhalte auflisten müssen. Für Ihr nächstes Projekt empfehle ich einen Blick in die Dokumentation des Content Query Field Type und das Webinar zur Vorstellung von Ibexa DXP v3.2 zu werden. Dort finden Sie einige Details zu den neuesten Verbesserungen.
Aspekte zur Erstellung umfangreicher Kundenerlebnisse
DXP E-Book
Wenn Sie mit Ihren digitalen B2B-Bemühungen im Bereich der digitalen Transformation zu kämpfen haben, warum wenden Sie sich nicht an uns, um Ihr Projekt zu besprechen? Laden Sie sich unser E-Book zur Digital Experience Platform (DXP) herunter und lesen Sie mehr zu den vier Aspekten zur Gestaltung außergewöhnlicher Kundenerlebnisse.
